
SEO蜘蛛池,探索百度蜘蛛池搭建的奥秘一、引言随着互联网技术的不断发展,搜索引擎优化,SEO,成为了网站提升流量、扩大影响力的关键手段,在SEO过程中,蜘蛛池,SpiderPool,的搭建成为了一个重要的环节,特别是在针对百度的优化中,百度蜘蛛池的搭建更是备受关注,本文将详细介绍SEO蜘蛛池的概念、作用,以及百度蜘蛛池搭建的方法与策略...。
更新时间:2026-03-14 11:57:12
SEO蜘蛛的含义与技术在SEO优化中的应用一、引言随着互联网技术的快速发展,搜索引擎优化,SEO,已经成为网站提升流量、提高排名和扩大品牌影响力的关键手段,在SEO领域中,蜘蛛,Spider,扮演着至关重要的角色,那么,SEO蜘蛛到底是什么意思,它在SEO技术中如何应用,本文将详细解析这一问题,二、SEO蜘蛛的基本概念1.定义,在SE...。
更新时间:2026-02-23 08:34:02

SEO蜘蛛,探索与优化网络世界的秘密武器=======================随着互联网技术的飞速发展,搜索引擎优化,SEO,成为了网站运营不可或缺的一环,在SEO领域中,蜘蛛,Spider,扮演着至关重要的角色,它们悄无声息地穿梭于网络世界,搜集信息、分析数据,为搜索引擎提供丰富的内容索引,本文将深入探讨SEO蜘蛛的工作原理...。
更新时间:2026-02-22 11:24:52

蜘蛛SEO,超级外链工具的力量与策略一、引言随着互联网技术的飞速发展,搜索引擎优化,SEO,已成为网站提升流量、扩大影响力的关键手段,在SEO领域中,蜘蛛,Spider,扮演了极为重要的角色,蜘蛛是一种用于在互联网上自动抓取、分析和索引网页的软件,其核心功能是搜索和抓取网站内容,而在实际操作中,很多站长发现通过合理的使用超级外链工具可...。
更新时间:2026-02-22 11:18:11
揭秘SEO蜘蛛,深入理解蜘蛛机制与蜘蛛池策略一、引言在搜索引擎优化,SEO,领域,蜘蛛,Spider,扮演了至关重要的角色,蜘蛛是搜索引擎用来爬行和抓取网页的工具,它们沿着网页上的链接不断爬行,收集数据并存储在搜索引擎的数据库中,本文将从SEO的角度出发,深入解析蜘蛛的工作原理,并探讨蜘蛛池策略的应用,二、SEO蜘蛛的基本原理1.蜘蛛...。
更新时间:2026-02-22 10:54:41

关于SEO蜘蛛池及其出租服务的探讨一、引言随着互联网技术的快速发展,搜索引擎优化,SEO,已成为网站提升排名、吸引流量的关键手段,而在SEO优化过程中,蜘蛛池,SpiderPool,发挥着举足轻重的作用,本文将详细介绍SEO蜘蛛池的概念、功能,并探讨SEO蜘蛛池出租服务的利弊,以帮助读者更好地了解和应用这一技术,二、SEO蜘蛛池概述1...。
更新时间:2026-02-22 10:51:11
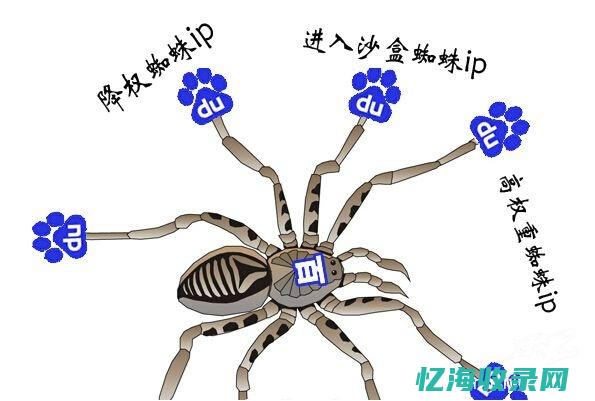
蜘蛛SEO与电影在线播放平台的机遇与挑战一、引言随着互联网技术的飞速发展,搜索引擎优化,SEO,对于网站的重要性日益凸显,蜘蛛,Spider,作为搜索引擎的核心组成部分,负责在互联网上抓取和索引网页内容,本文将从蜘蛛SEO的角度出发,探讨其在电影在线播放平台中的应用及其所面临的机遇与挑战,同时,我们将关注蜘蛛森林电影普通话在线播放这一...。
更新时间:2024-12-28 09:34:34
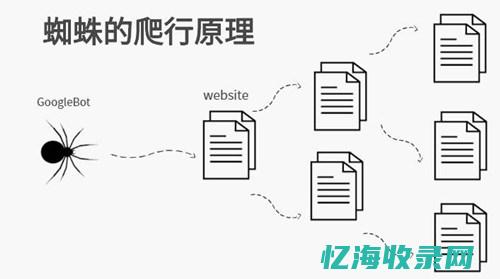
蜘蛛SEO超级外链工具与教程一、引言随着互联网技术的飞速发展,搜索引擎优化,SEO,在网站运营中的重要性日益凸显,搜索引擎蜘蛛,Spider,作为SEO的核心组成部分,负责抓取网页内容并生成索引,而外链建设则是SEO工作中的关键环节之一,对于提升网站排名及权重具有重要意义,本文将介绍一款名为,蜘蛛SEO超级外链工具,的强大工具,以及如...。
更新时间:2024-12-28 08:03:29
SEO基础知识点详解一、搜索引擎优化,SEO,概述搜索引擎优化,SEO,是一种通过对网站内容、结构和链接进行优化,以提高网站在搜索引擎结果页,SERP,的排名,从而增加网站流量和转化率的技术,随着互联网的发展,SEO已成为网站推广和营销的重要手段,二、SEO基础知识点1.搜索引擎工作原理搜索引擎主要通过爬虫,Spider,程序来收集互...。
更新时间:2024-12-15 08:06:53

如何确认您的网站是否被网络收录以及如何提高被收录的机会是很多网站所有者关心的问题,网络的收录机制注重用户体验,因此符合用户搜索需求的网站和网页更容易被网络Spider发现和收录,为了快速让网络发现您的站点,您可以通过向网络提交您网站的入口网址来提高被收录的可能性,您可以在百度的搜索引擎提交地址,baidu,search,url,sub...。
更新时间:2024-05-15 15:42:26

本文详细分析了如何检查网站是否被网络收录以及如何让个人网站或博客被网络搜索引擎所收录,网络收录的重要性在于提升网站在搜索结果中的曝光度,进而增加流量和访问量,作者指出,为了让网络Spider更快地找到您的网站,可以通过向网络提交网站的入口网址来加快收录的过程,提交的方法包括直接向网络提交首页网址,如通过百度搜索的URL提交页面进行操作...。
更新时间:2024-05-15 14:24:36

本文详细介绍了网站收录的流程和方法,以及一些常见的网络搜索站点的提交入口,作者列举了各种不同的网络搜索站点,包括必应、雅虎中国、网易有道、搜猫、博客大全等,展示了如何通过这些平台提交自己的网站以便被收录,作者指出,网络收录与网站的内容质量直接相关,与商业因素如竞价排名无关,为了让网络Spider更快地找到并收录网站,作者建议可以通过向...。
更新时间:2024-05-15 13:38:26

对于如何查看网站是否被网络收录以及如何让你的网站被网络收录,以下是详细分析,网络的网页收录机制主要与网页的价值相关,与商业因素无关,为了让网络Spider更快地发现你的站点,可以提交你的网站入口网址到百度的提交地址,baidu,search,url,submit,只需提交首页即可,无需提交详细内容页面,要验证你的网站是否被网络收录,可...。
更新时间:2024-05-15 13:16:38

一直以来百度Spider对图片、视频、CSS、Javacript的抓取识别能力是比较低的,甚至很多都是识别不了的,近日,百度搜索引擎官方发布了一篇关于提升百度Spider抓取能力提升的公告,...。
更新时间:2024-01-26 17:11:23

搜索引擎优化SEO的原理和策略是什么啊具体介绍谢啦原理是,吸引百度spider提供食物,吸引是网站首页链接的发布包括外链和内链,食物是本身网站更新的文章内容,策略是,对站内高质量如何优化架构来合理安排网站以及不断及时更新补充网站内容,对外发布高质量锚文本外链以及纯文本外链来提高网站权重以及网站曝光率和流量,纯手打,希望能够帮助您,什么...。
更新时间:2024-01-18 08:18:58

Baiduspider、Googlebot、360Spider…,…,妇孺皆知,只要被搜查引擎蜘蛛抓取并被收录的页面,才有或者介入到排名的竞争中,所以如何建设网站与,蜘蛛,之间的咨询,是各位站长最为关注的疑问,搜查引擎蜘蛛…。
更新时间:2024-01-08 10:20:18

腾讯云3年,5年主机,点击抢每日限量秒杀名额阿里云主机99元,年,速抢活动名额腾讯云新客无门槛满减券,限量速抢阿里云活动核心活动券,点击速抢形成美国主机带宽跑满的起因有,1、经常使用美国主机环节中遭逢大规模网络攻打造成;2、美国主机遭到木马病毒以及站点挂马的影响造成;3、美国主机后盾存在少量消耗资源进程造成;4、美国主机网站发生少量爬...。
更新时间:2024-01-02 12:52:09

搜索引擎蜘蛛劫持是seo黑帽中常用的一种手法,需要一定的技术支持getshell,然后上传恶意的代码到网站根目录下面或者修改网站的一些文件,搜索引擎蜘蛛劫持的原理就是判断来访网站的是用户还是蜘蛛,如果是蜘蛛就推送一个事先准备的恶意网站,如果是用户就推送一个正常的网页1,蜘蛛判断判断访问的是用户还是蜘蛛,如果是用户就推送一个正常网页,如果是蜘蛛就推送一个恶意网页,判断方式有两种,一种是判断蜘蛛的UA,一种是蜘蛛的ip段2,蜘蛛劫持代码判断如果是百度,360,搜狗,神马蜘蛛就返回恶意的网页给蜘蛛,如...。
更新时间:2023-12-28 03:40:56

尽管搜索引擎在不断的升级算法,但是终究其还是程序,因此我们在布局网站结构的时候要尽可能的让搜索引擎蜘蛛能看的懂,每个搜索引擎蜘蛛都有自己的名字,在抓取网页的时候,都会向网站标明自己的身份,搜索引擎蜘蛛在抓取网页的时候会发送一个请求,这个请求中就有一个字段为User-agent,用于标识此搜索引擎蜘蛛的身份,例如Google搜索引擎蜘蛛的标识为GoogleBot,百度搜索引擎蜘蛛的标识为Baiduspider,Yahoo搜索引擎蜘蛛的标识为InktomiSlurp,如果在网站上有访问日志记录,...。
更新时间:2023-12-28 03:39:10

近期百度搜索最大的动作应该就是百度Spider3.0升级了,简单的概括下升级的特点就是,抓取更实时,收录效率更快,对原创优质内容更青睐,此次升级是把当前离线、全量计算为主的系统,改造成实时、增量计算的全实时调度系统,万亿规模的数据进行实时读写,可以收录90%的网页,速度提升80%!,抓取、建库更快—提交的内容更容易被抓取,链接发现方面,如今sipder每天发现的新链接在500亿左右的量级,说明啥,你的站点内容越来越容易被Spider发现和抓取,而在百度站长平台提交链接是最为高效的,但是百度工程师...。
更新时间:2023-12-28 03:37:50
 网站首页
网站首页 提交收录
提交收录 收录查询
收录查询 文章资讯
文章资讯 热门排行
热门排行 软文发布
软文发布 自助广告
自助广告