Meta森林图是一种用于展示大规模数据集中变量之间关系的可视化工具。
通过对多维数据进行可视化处理,Meta森林图有助于研究人员更直观地理解复杂数据,从而发现数据中的模式、趋势和关联。
本文将详细介绍如何解读Meta森林图以及制作Meta森林图的步骤。
1. 结构与元素:Meta森林图由节点、连接线和点等元素组成。节点代表变量或特征,连接线表示变量之间的关系,点的颜色和大小可能代表不同的数据特征或度量值。
2. 关系分析:通过解读节点之间的连接线,可以分析变量之间的直接和间接关系。理解这些关系对于理解数据背后的模式至关重要。
3. 重要性评估:在Meta森林图中,某些节点可能比其他节点更重要,这通常通过节点的大小、颜色或形状来表示。通过评估这些重要性,可以优先关注关键变量。
4. 异常检测:通过对比图中的异常值或离群点,可以检测数据中的异常值或噪声。这对于数据清洗和异常处理非常有帮助。
1. 数据准备:需要准备用于生成Meta森林图的数据集。数据集应包含要分析的变量和对应的数据值。
2. 数据预处理:在数据预处理阶段,需要清理和整理数据,确保数据的准确性和一致性。这可能包括处理缺失值、异常值和重复数据等。
3. 选择分析方法:根据研究目的和数据特点,选择合适的分析方法。在这里,我们将使用Meta森林图进行分析。
4. 生成Meta森林图:使用专门的软件或工具生成Meta森林图。这些工具通常提供丰富的自定义选项,如颜色、形状、大小等,以便更好地展示数据特点。
5. 解读与验证:在生成Meta森林图后,对其进行解读并验证结果。检查变量之间的关系、关键变量的重要性以及异常值等,以确保结果的准确性。
1. 数据准备:收集相关数据并将其整理成适合分析的格式。确保数据的准确性和完整性。
2. 数据预处理:处理缺失值、异常值和重复数据等,以提高数据质量。还可能需要进行数据标准化或归一化等预处理操作。
3. 选择分析方法:根据研究目的和数据特点,选择适当的分析方法。在这里,我们选择使用Meta森林图进行分析。
4. 选择合适的软件或工具:市面上有许多软件或工具可用于生成Meta森林图,如R语言、Python等。选择合适的工具,根据工具的文档和指南进行安装和配置。
5. 生成Meta森林图:使用所选工具加载数据并生成Meta森林图。在生成过程中,可以根据需要调整节点的颜色、形状、大小等属性,以更好地展示数据特点。
6. 解读与验证:观察和分析生成的Meta森林图。检查变量之间的关系、关键变量的重要性以及异常值等。如果结果不符合预期,可能需要检查数据或调整分析方法。还可以与其他分析方法的结果进行对比,以验证结果的准确性。
通过本文,您应该已经了解了如何解读Meta森林图以及制作Meta森林图的步骤。
我们需要准备数据并进行预处理。
选择合适的分析方法和工具来生成Meta森林图。
最后,对生成的Meta森林图进行解读和验证。
通过这种方法,我们可以更好地理解和分析大规模数据集,发现数据中的模式、趋势和关联。
需要注意的是,在进行数据分析时,我们还应结合其他分析方法,以获取更全面和准确的结果。
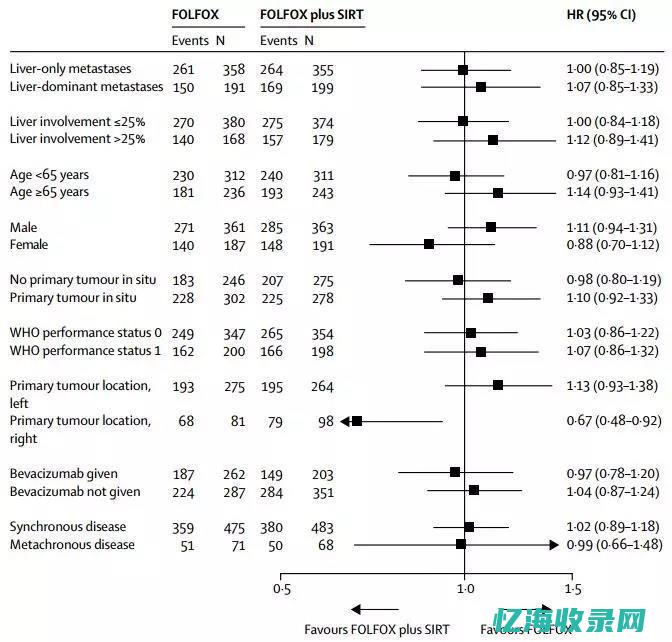
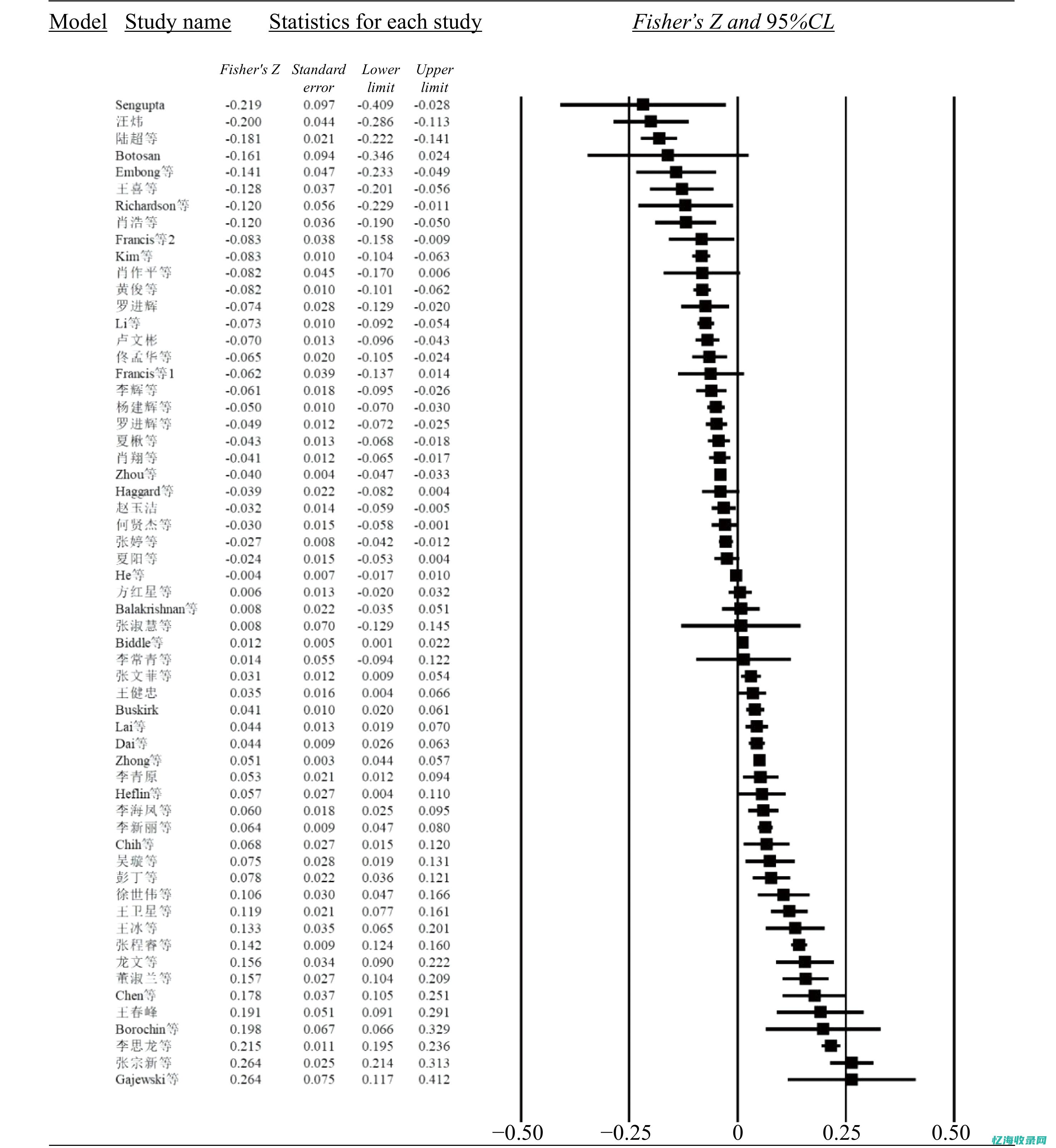
图形在结果展示上具有显著优势,在Meta分析中扮演着关键角色。 以下是一些Meta分析中常用的图形,供研究者参考:一、流程图展示原始研究的纳入排除过程二、森林图,并标注必要的统计检验结果(如异质性检验)以展示Meta分析的结果三、漏斗图或Galbraith图等展示原始研究效应值的分布情森键瞎况或相互关系,以评估发表偏倚的可能性四、气泡图展示Meta回归结果一、纳入排除流程图纳入排除流程图通常在结果中首先展示亮并,描述了原始研究的纳入排除过程。 PRISMA提供的流程图模板值得推荐。 具体示例与建议如图1所示。 图1. PRISMA 2009 纳入排除流程图绘图建议:1、流程图上方展示初始获取的文献数量,下方展示最终纳此空入分析的文献数量,中间部分展示文献的纳入排除过程。 2、流程图可分为四部分:文献获取、文献筛选、文献入排和文献纳入。 3、向下的箭头表示文献选择过程,向右的箭头表示每一步中排除的文献和原因。 二、森林图森林图是Meta分析结果中的经典图形,由图形和数据列表两部分组成。 它起源于20世纪70年代,因其线条类似森林而得名。 数据列表包含各原始研究及样本量、结局事件数、效应值等信息,原始研究的排列一般应遵从一定顺序,如发表年代或贡献的权重。 效应值通常为均数差、OR、RR或HR等,并提供置信区间。 在合并效应值时,方差越小的研究权重越大。 固定效应模型假定各原始研究的效应一致,权重通常等于各原始研究方差的倒数。 随机效应模型假定各原始研究效应不一致,但服从一定分布,其权重包含研究间的方差。 除了展示各原始研究间的数据外,研究间效应值的异质性也需要进行报告,推荐使用I2统计量衡量异质性大小。 如果进行了亚组分析,森林图中应将各亚组分别展示,并计算I2衡量亚组间的效应值异质性大小。 如果统计学检验显示,不能认为亚组间效应存在异质性,那么应该将亚组进行合并。 图形部分展示了各研究效应值及其95%CI区间,图中点的大小衡量各研究贡献的权重大小。 图的最底部为Meta分析的合并值。 具体示例(图2)与绘图建议如下:绘图建议:1. 数据列表部分(1) 展示纳入分析的原始研究。 研究排列应遵从一定顺序,如发表年代,权重大小或作者首字母(2) 给出各原始研究的结局事件数(3) 给出各组的样本量(4) 给出各原始研究贡献的权重
研究中常用的效应尺度指标包括 结局为分类变量 时的odds ratio(OR)、relative risk(RR)和risk difference(RD),以及结局为 连续性变量 时的weighted mean difference(WMD) 和standardizedmean difference(SMD)。
是测量疾病与暴露联系强度的一个重要指标。 是某组中某事件的比值与另一组内该事件的比值之比。 OR=1 表示比较组间没有差异。 当研究结局为不利事件时,OR<1 表示暴露可能会降低结局风险。
国内翻译为“ 相对危险度”,其意义为两组的事件率之比。 RR 是反映暴露(干预)与事件关联强度的最有用的指标。 RR=1 表示比较组间没有差异。 当研究结局为不利事件时,RR<1 表示干预可降低结局风险。 需要注意的是, 只有队列研究和随机对照试验结果 可以直接获得相对危险度。
也被称为归因危险度(attributable risk,AR)、绝对风险差(absoluterisk difference)和绝对风险降低率(absolute riskreduction, ARR),是指干预(暴露)组和对照组结局事件发生概率的绝对差值。 RD反映了暴露(干预)组中净由暴露(干预)因素所致的发液陪病水平(从暴露组角度考虑)。 RD=0表示比较组间没有差异。 当研究结局为不利事件时,RD<0 表示干预可降低结局风险。 通常只有队列研究和随机对照试验结果可以计算RD。
用于Meta 分析中所有研究具有相同连续性结局变量(如体重)和测量单位时。 计算WMD 时,需要知道每个原始研究的均数、标准差和样本量。 每个原始研究均数差的权重(例如每个研究对Meta分析合并统计量的影响大小)由其效应估计的精确性决定。
为两组估计均数差值除以平均标准差而得。 由于消除了量纲的影响,因而结果可以被合并。
最常用的软件主要包括RevMan软件。 STATA软件和R软件,我们在接下来的推送中也会介绍RevMan和STATA软件实现森林图的方法。
需要注意的是RevMan 绘制的森林图, 系统默认的研究事件是“不利事件” , 如发病、患病、死亡等, 即系统默认森林图横坐标的左侧为“favours treatment” , 其横坐标的右侧为“favours control”。
也就是说, 无论是二值变量的指标OR或RR, 还是连续变量的指标WMD 或SMD , RevMan 绘制的森林图,只要其系统默认某个研究的95 %CI 的横线不与森林图的无效线相交且落在无效线左侧, 可认为试验物埋掘组的试验因素会减少不利事件的发生, 试验因素为有益因素(保护因素), 即试验因素有效。
但是, 当研究的事件是“有利事件”时, 若需要在RevMan中绘制森林图, 则应修改其系统默认值, 即将横坐标的左侧修改为罩核“favours control” , 将横坐标的右侧修改为“favours treatment”。 否则, 采用系统默认值的森林图是错误的。
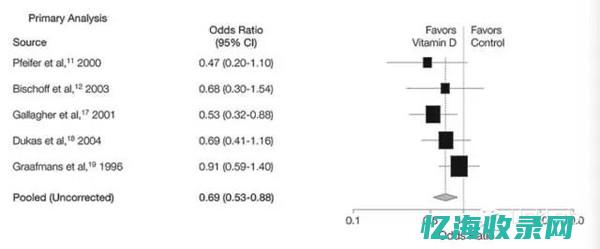
您好!这个是用Revman数据分析软件做循证医学Meta分析时,结果里面的森林图。 应该这么来喊森解答图里面所包含的信息:1、一共纳入了8篇文献,总共纳入的干预组例数为370例,对照组人数为303例。 这8篇文献都分别进行了辩证护理与常规护理对好转病人人数的对比。 (因为你没有给出具体是对什么结局指标的桐谈影响,故我暂定为病人好转人数吧。 )2、倒数第二排文字中,卡方值为2.44,P=0.88>0.05,I²=0%,说明异质性低,采用固定效应模型计算合并效应量OR值。 3、从这个结果可以看出:合并郑轮亩效应量OR值为3.31,OR值95%可信区间是2.20~4.97。 这个区间不包括1,可以认为合并的效应量OR值不等于1,也即:辩证护理与常规护理导致的病人好转数不一样,存在统计学差异。 又由于整个可信区间都大于1,固然说明:辩证施护比常规施护的病人好转人数要多些,也即:辩证施护的效果要好于常规施护。 还有什么不懂的,随时问我,我就是搞这个研究的。 谢谢!
标签: meta森林图的解读、 meta森林图制作步骤、本文地址: https://yihaiquanyi.com/article/e76c45464445c7512dc2.html
上一篇:东莞seo优化公司东莞seo建站优化哪里好... 网站首页
网站首页 提交收录
提交收录 收录查询
收录查询 文章资讯
文章资讯 热门排行
热门排行 软文发布
软文发布 自助广告
自助广告