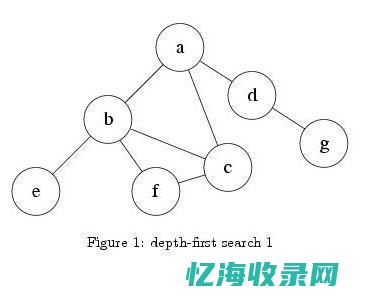
深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索树或图的算法。
此算法会尽可能深地搜索树的分支,当节点v的所在边都已被探寻过,搜索将回溯至发现节点v的那条边的起始节点。
在这个过程中,深度优先搜索使用了一种称为栈的数据结构来记录待探索的节点。
与此不同,广度优先搜索则更倾向于使用队列数据结构。
本文将对深度优先搜索的原理、实现及应用进行详细介绍,并阐述为何选择使用栈而非队列。
深度优先搜索是一种用于遍历或搜索树或图的算法,其主要目标是访问图中的所有顶点,且仅访问一次。
这种算法从根(或任何一个节点)开始,并沿着每个可能的路径深入到图的深处,直到达到目标节点或者无路可走。
如果目标节点无法直接到达,那么算法会回溯到之前的节点,并尝试其他未探索的路径。
通过这种方式,深度优先搜索能够尽可能地深入到图的深处,从而找到目标节点。
深度优先搜索的实现通常使用递归或者迭代的方式。
在递归实现中,算法会不断地调用自身来处理子节点,直到达到目标节点或者无路可走。
递归方式可能导致函数调用栈溢出,尤其是在处理大型图或树时。
为了避免这个问题,我们通常使用迭代方式实现深度优先搜索,而这就需要使用到栈这种数据结构。
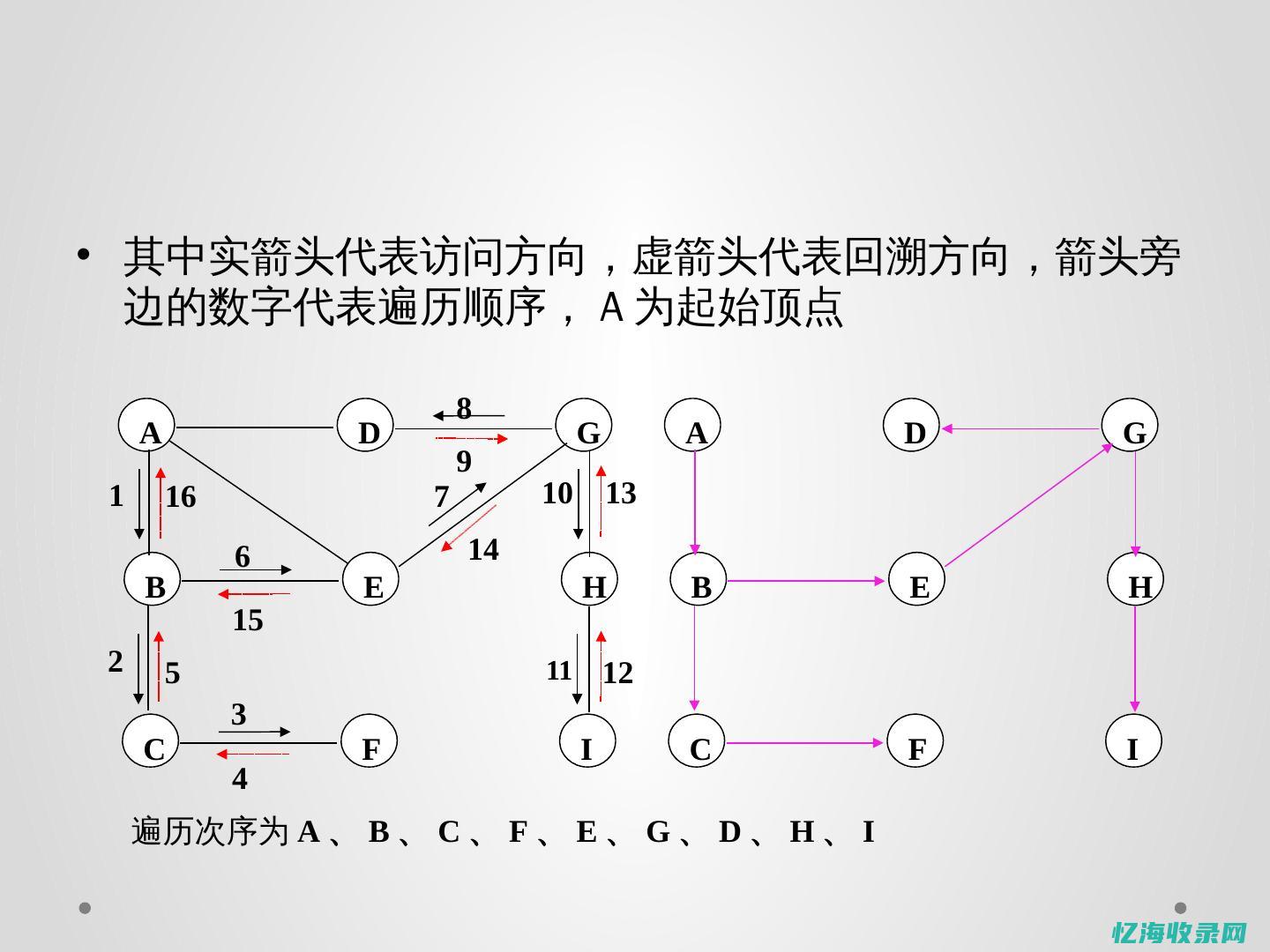
在深度优先搜索中,我们使用栈来记录待探索的节点。
当我们探索到一个节点时,我们将这个节点的所有未探索的邻居节点压入栈中。
我们从栈顶取出一个节点进行探索。
当所有相邻节点都被探索过后,我们弹出栈顶节点并回溯到前一个节点。
这个过程会一直持续下去,直到我们探索完所有的节点或者找到目标节点。
使用栈可以实现深度优先搜索的迭代实现,从而避免递归的潜在问题。
相较于广度优先搜索使用的队列数据结构,深度优先搜索选择使用栈的原因在于其更适合处理深度方向的探索。
在树的遍历过程中,我们更关心的是沿着每个可能的路径深入到图的深处,直到找到目标节点或者无路可走。
而队列更适合处理广度方向的探索,即同时探索所有相邻节点,这是广度优先搜索的特点。
因此,对于深度优先搜索来说,使用栈更为合适。
深度优先搜索在图论、计算机科学、人工智能等领域有着广泛的应用。
例如,在图论中,深度优先搜索可以用于找到从一个节点到另一个节点的路径、检查图是否连通等。
在计算机科学中,深度优先搜索可以用于解决许多问题,如编译器的语法分析、网页爬虫等。
在人工智能领域,深度优先搜索可以用于游戏AI、自然语言处理等方面。
深度优先搜索也是许多复杂算法的基础组成部分,如最短路径算法、最小生成树算法等。
深度优先搜索是一种用于遍历或搜索树或图的算法,其使用栈这种数据结构来记录待探索的节点。
相较于广度优先搜索使用的队列数据结构,深度优先搜索选择使用栈的原因在于其更适合处理深度方向的探索。
本文详细阐述了深度优先搜索的原理、实现方式以及应用,并解释了为何选择使用栈而非队列来实现深度优先搜索。
希望本文能帮助读者更好地理解深度优先搜索及其实现方式。
本文地址: https://yihaiquanyi.com/article/e500492d62e6557c346a.html
上一篇:seo诊断工具seo诊断优化方案... 网站首页
网站首页 提交收录
提交收录 收录查询
收录查询 文章资讯
文章资讯 热门排行
热门排行 软文发布
软文发布 自助广告
自助广告